AI-Powered Payment Routing: How ML Replaced the Static Routing Table
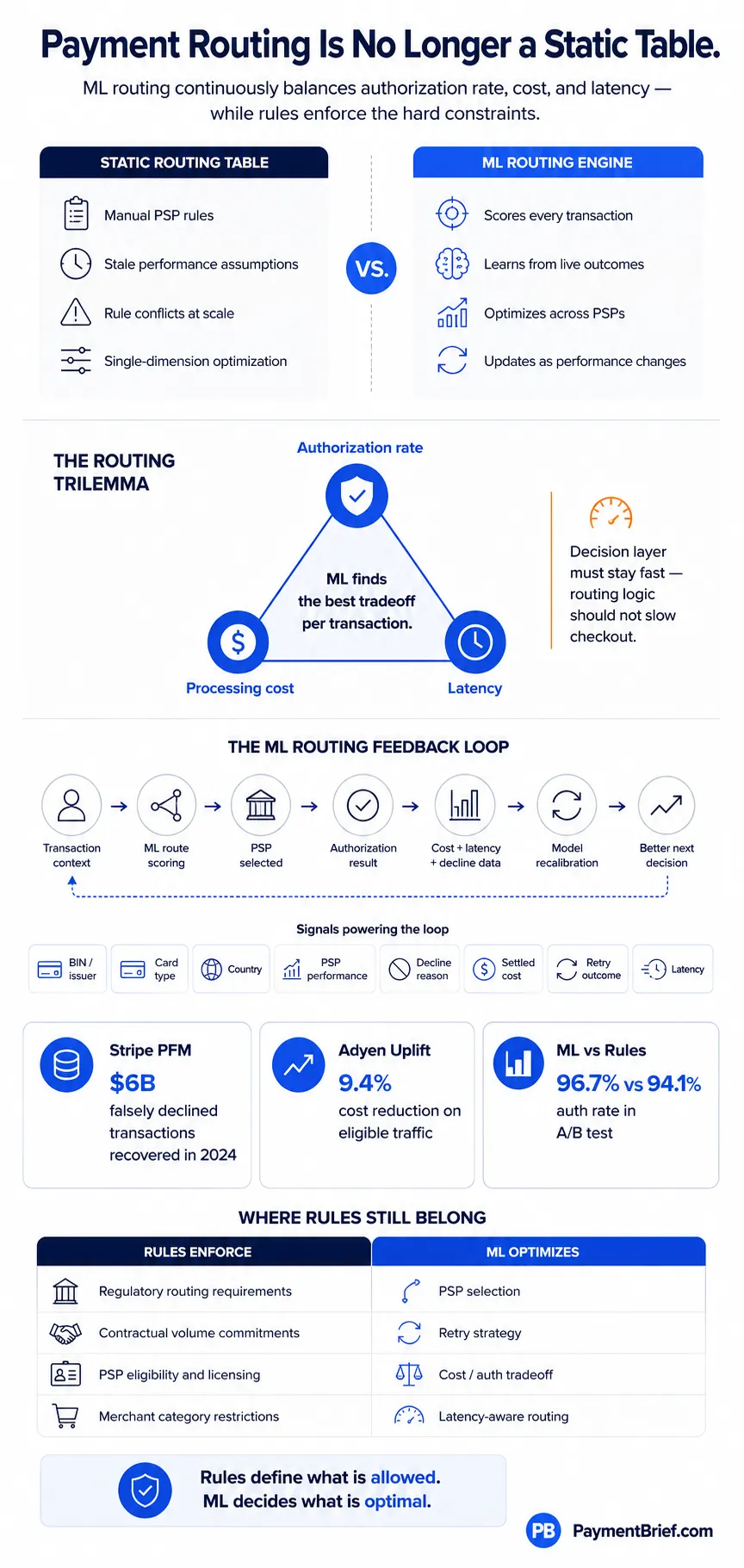
Static routing rules freeze yesterday's PSP performance. ML routing learns from authorization outcomes to continuously optimise cost, auth rate, and latency.
Stripe PFM (May 2025): tens of billions of transactions, $6B falsely declined txns recovered in 2024. Adyen Uplift (Jan 2025): 9.4% cost reduction, 42% fewer false declines. ML routing: 96.7% vs 94.1% auth rate vs rules (A/B, 200K txns, sub-30ms decisions).
AI payment routing uses ML models to make per-transaction PSP selection decisions in real time, replacing static rule tables with models that learn continuously from authorization outcomes. Stripe's Payments Foundation Model (May 2025), trained on tens of billions of transactions, drives Authorization Boost (3.8% average auth rate uplift) and recovered $6B in falsely declined transactions in 2024. Adyen's Intelligent Payment Routing achieved 26% cost savings and 0.22% auth rate uplift on US debit. ML routing systems make routing decisions in under 30ms. The trilemma: optimizing for auth rate, cost, and latency simultaneously requires ML — static rules can optimize for one dimension at the expense of the others.
A static routing table is a frozen snapshot of how your PSPs performed last quarter. If Stripe had a better auth rate on UK Visa cards in December, your rules say route UK Visa to Stripe — until someone updates the table. Nobody updates the table. Meanwhile the issuer shifts its approval thresholds, a new PSP relationship you built in Q1 outperforms the old one, and your rules are quietly leaving authorization rate and margin on the table.
ML payment routing replaces the static table with a model that learns from every transaction outcome. It scores each payment against real-time PSP performance signals, predicted authorization probability, processing cost, and latency constraints — and picks the optimal route. The difference is compounding: every transaction is training data for the next decision.
The multi-acquirer routing architecture article covers when to add a second PSP and how orchestration platforms are structured. This article covers the intelligence layer on top — how ML makes the routing decision, what the major platforms are actually doing, and the trilemma at the center of every routing model.
The Problem With Static Rules at Scale
Small merchants with one or two PSPs don't have a routing problem. At scale — cross-border, multi-currency, multiple acquirers, high transaction volumes — static rules break down in predictable ways.
Rule explosion. The first routing rule is simple: route to PSP A for domestic cards, PSP B for international. Then someone adds a rule for high-value transactions. Then a rule for specific BIN ranges with poor performance on PSP A. Then a rule for weekend traffic. Three years later you have 200 rules, nobody knows which ones conflict, and touching any of them requires a post-mortem level of caution. Static payment orchestration tables don't scale with transaction complexity — they accumulate technical debt.
Stale weights. Issuer authorization behavior changes constantly. An issuer tightens approval thresholds for a card type, or improves its fraud models and starts approving more transactions that were previously soft declines. Your rules were calibrated on last year's data. The performance delta between what your rules predict and what's actually happening widens over time without continuous recalibration.
Single-dimension optimization. A rule that says "route to the cheapest acquirer" optimizes for cost at the expense of authorization rate. A rule that says "route to the PSP with the highest historical auth rate" ignores cost and may not account for latency on cross-border transactions. Static rules can't optimize across multiple dimensions simultaneously — they pick one and accept the tradeoffs on the others.
ML routing solves all three: it handles arbitrary complexity without rule proliferation, it recalibrates continuously from live outcomes, and it finds the optimal point across cost, auth rate, and latency simultaneously per transaction.
The Trilemma: Cost, Authorization Rate, and Latency
Every routing model is solving a three-dimensional optimization problem, and the three dimensions trade off against each other in ways that are worth understanding explicitly.
Auth rate vs. cost. The PSPs with the highest authorization rates are typically the ones with the deepest issuer relationships, the most routing intelligence, and the most invested infrastructure — which also makes them more expensive. Routing to the cheapest acquirer available often produces lower authorization rates. ML routing finds the crossover point: where the cost savings from a cheaper PSP exceed the revenue cost of the auth rate delta — and one auth rate point is worth more than most operators realise.
Auth rate vs. latency. Retry logic — attempting authorization on a second PSP when the first declines — significantly improves auth rate on soft declines but increases total transaction latency. For most e-commerce transactions, a 200ms retry window is invisible to the customer and worth the auth rate uplift. For real-time payment contexts or checkout flows where conversion drops with page load time, the latency cost may not be worth it. ML routing parameterizes this tradeoff per merchant category and transaction type.
Cost vs. latency. More routing intelligence means more compute, more feature retrieval, and more inference time. The routing decision itself needs to run in under 30ms to stay within the 100ms total authorization window. This creates a hard latency constraint that bounds model complexity. You cannot run a 500-parameter transformer per transaction in 30ms without dedicated GPU inference infrastructure — which is why Stripe's partnership with NVIDIA for the Payments Foundation Model is an infrastructure story as much as a model story.
The practical implication: no single routing configuration is globally optimal. ML routing adapts the optimization weights per transaction context — for a high-value transaction in a tight merchant margin business, the cost weight increases; for a subscription renewal on a card that has declined three times before, the auth rate weight dominates.
What the Major Platforms Are Actually Doing
Stripe: Payments Foundation Model and Authorization Boost
Stripe announced its Payments Foundation Model (PFM) in May 2025 — a transformer-based model trained on tens of billions of transactions using self-supervised learning, built in partnership with NVIDIA for real-time inference. Where prior ML systems used many specialized models (one for fraud, one for retry scoring, one for authorization optimization), the PFM generates a universal behavioral embedding per transaction — a numerical representation of the payment's full context — that powers multiple downstream products from a single model.
The most operator-relevant output is Authorization Boost, which combines Stripe's auth rate optimization tools into a single product delivering 3.8% average uplift across eligible merchants. The underlying mechanism is Adaptive Acceptance: the model identifies transactions that were declined but would likely succeed on retry (false declines), retries them in real time without the customer seeing the initial decline, and continuously improves on which declines are worth retrying. In 2024, Adaptive Acceptance recovered $6 billion in falsely declined transactions — a 60% year-on-year increase in retry success rate. The PFM also increased detection of coordinated attacks on large businesses by 64% at launch.
The Zapier case study is illustrative: Stripe's ML layer generated a 1.24% auth rate uplift from Adaptive Acceptance ($1M+ in additional revenue) plus a 2.76% uplift from Card Account Updater — total $3M+ in additional annual revenue from optimization alone. This is the math operators need to apply to their own transaction volumes when evaluating AI routing investment.
Adyen: Uplift and Intelligent Payment Routing
Adyen launched Uplift in January 2025 — a bundled optimization layer combining intelligent routing, network token optimization, and false decline reduction. In its first year, Uplift delivered 9.4% cost reduction on eligible traffic and 42% fewer false positive transaction blocks on average.
The routing component is clearest in Adyen's Intelligent Payment Routing for US debit under Durbin Amendment least-cost routing requirements. The Durbin Amendment requires issuers to enable at least two unaffiliated debit networks on each card — giving acquirers a choice of which network to route over, with dramatically different costs. Adyen's AI selects the lowest-cost network that will yield the highest authorization rate for each debit transaction, rather than applying a static cost-only or auth-only rule. In a pilot with over 20 enterprise merchants including eBay, Microsoft, and 24 Hour Fitness, this delivered 26% cost savings and a 0.22% authorization rate uplift simultaneously — a result that proves the trilemma can be navigated rather than accepted.
Primer, Gr4vy, and the Orchestration Layer
For merchants not on Stripe or Adyen as primary processors, orchestration platforms provide the ML routing layer independently of any single PSP. Primer connects to multiple PSPs through a unified integration and applies routing logic at the orchestration layer — allowing merchants to run ML-driven routing across PSPs without rebuilding integrations per provider. Gr4vy distributes transactions across PSPs based on real-time performance metrics, updating routing scores from live authorization outcomes rather than cached historical data. Both platforms allow operators to define the optimization objective (auth rate weighted, cost weighted, or balanced) and let the model handle per-transaction execution.
The orchestration layer approach has a specific advantage: it accumulates routing performance data across PSPs that individual PSPs don't share with each other. An orchestration platform sees that PSP A performs 2.3pp better than PSP B on UK Visa transactions between £50-£200 on weekday evenings — a signal that neither PSP A nor PSP B can observe independently.
The Feedback Loop: Why ML Routing Compounds
The mechanism that makes ML routing fundamentally different from static rules is the feedback loop. Every routing decision generates telemetry: which PSP was selected, the predicted authorization probability, the actual authorization outcome, the decline reason code if declined, the processing cost, and the end-to-end latency. This data feeds back into the model on a continuous or near-continuous basis.
The practical implications are significant. A new PSP relationship that outperforms expectations starts receiving more traffic within days, not after the next manual rule update. An issuer that tightens its approval criteria for a BIN range produces more declines on that BIN — the model detects the performance degradation and shifts traffic away before a human analyst would notice the trend. A PSP that improves its issuer connectivity after infrastructure upgrades gets credited with the improvement in the model's weights.
This is also why the quality of the feedback signal matters. Online metrics — auth rate, latency — are immediate but incomplete. Actual processing costs are confirmed at settlement, which lags transactions by one to two business days. ML routing models need to reconcile online routing decisions with offline cost data to avoid systematic errors where quoted fees don't match settled fees. Operators building in-house routing intelligence should instrument both signal paths from the start. See the authorization optimization guide for the full signal set worth collecting.
Where Static Rules Still Belong
ML routing doesn't eliminate rules — it changes what rules are for. Static rules should encode constraints, not performance guesses.
Regulatory requirements that mandate specific network routing paths (e.g., Durbin LCR requirements, specific card type rules under national scheme regulations) must be enforced as hard rules before the ML model scores options.
Contractual minimums with acquirers — volume commitments that require a minimum percentage of traffic to route to a specific PSP — are business constraints that the model should respect as floors, not optimize away.
Merchant category sensitivities where a specific PSP has the necessary licensing or risk appetite for a transaction type (gambling, digital goods, regulated financial products) should be encoded as eligibility rules. The ML model scores among eligible PSPs; it doesn't make licensing decisions.
The rule engines vs ML hybrid architecture article covers this design pattern in depth for fraud stacks — the same layered approach applies to routing: ML optimizes within a rules-defined eligibility set. Rules that encode optimization guesses ("route UK Visa to PSP A because it performed best last year") should be replaced with ML. Rules that encode constraints should stay.
The Explainability Question
Acquirer relationships carry an implicit expectation of volume. If your ML model starts routing a materially lower percentage of transactions to an acquirer whose performance has declined, that acquirer will notice. This creates an operational reality that pure optimization logic doesn't account for: acquirers provide commercial terms, support, and relationship capital in exchange for volume — and an AI that silently redistributes volume without explanation can damage relationships that took years to build.
The practical answer is transparency, not manual override. Operators running ML routing should be able to pull a performance attribution report showing why traffic shifted — which PSP performance metric drove the change, the magnitude of the performance delta, and the authorization rate or cost impact of the shift. This is the explainability layer that matters commercially, not model interpretability in the academic sense. When your acquirer relationship manager asks why volume dropped 15% last month, "the AI decided" is not a satisfactory answer. "Auth rate on UK Visa cards declined from 87.3% to 84.1% over 30 days — here's the data" is.
What Operators Should Do
If you're on Stripe and not using Authorization Boost: enable it. The 3.8% average uplift is the most accessible free performance improvement in the stack. The Payments Foundation Model is also processing your transactions whether you enable the optimization products or not — turning on Authorization Boost is an opt-in to the optimization outputs, not additional infrastructure.
If you're on Adyen and not on Uplift: review the 9.4% cost reduction figure against your processing volume. At $10M monthly processing, that's a material number. The US debit routing improvement is particularly impactful for merchants with significant American debit card volume.
If you're on a third-party orchestration layer (Primer, Gr4vy, Spreedly): verify whether ML routing is active by default or requires configuration. Most platforms offer rule-based routing as the default and ML routing as an activated feature — check your configuration, not just your contract.
If you're building routing logic in-house: start with gradient boosting on historical transaction data before investing in transformer architectures. The Stripe PFM is a product of years of transaction data accumulation and NVIDIA-scale inference infrastructure. The right first step for most operators is gradient boosting with decline reason codes, BIN-level features, and PSP performance signals — not a foundation model. See also AI fraud detection for the feature engineering patterns that translate directly to routing models.
Instrument the feedback loop before optimizing. The model is only as good as the signal quality. Ensure you're capturing actual settled costs (not quoted rates), decline reason codes at the issuer level (not just acquirer-mapped codes), retry outcomes, and end-to-end latency. The scheme fees and interchange data that feed into cost calculations are the most commonly missing signal in in-house routing implementations.
Sources & methodology (8)
Stripe Payments Foundation Model announced May 2025 — transformer trained on tens of billions of transactions, NVIDIA partnership for real-time inference
Checked:
Stripe Adaptive Acceptance (TabTransformer+) recovered $6B in falsely declined transactions in 2024 — 60% YoY retry success rate increase
Checked:
Stripe Authorization Boost delivers 3.8% average auth rate uplift; Zapier case study: $3M+ additional revenue
Checked:
Adyen Intelligent Payment Routing: 26% cost savings, 0.22% auth rate uplift on US debit (pilot: eBay, Microsoft, 24 Hour Fitness)
Checked:
Adyen Uplift launched January 2025 — 9.4% cost reduction on eligible traffic, 42% fewer false positive declines
Checked:
ML routing A/B test: 96.7% auth rate vs 94.1% rule-based (200,000 transactions); decision latency under 30ms
Checked:
Stripe PFM increased detection rate for attacks on large businesses by 64% at launch
Checked:
Enterprises processing 10M+ transactions monthly see 30-40% cost reductions from ML payment orchestration
Checked:
Source types explained in our Methodology.