AI Fraud Detection in 2026: What the Models Are Actually Doing
Stripe unveiled a foundation model for payments fraud in 2025. Sardine reduced account takeover by 34.8% using behavioral biometrics. Here's what.
Production AI fraud detection in 2026 runs ensemble models combining supervised transaction scoring, unsupervised anomaly detection, and behavioral biometrics — delivering 30–40% fraud reduction while cutting false positives.
AI fraud detection has moved from rules augmentation to model-first architecture over the past three years, and the performance gap between operators who made that transition and those still running primarily rule-based systems is measurable in authorization rates and chargeback ratios. Stripe's 2025 State of AI and Fraud report documented a 42% reduction in SEPA fraud and a 20% reduction in ACH fraud for Radar users (Stripe, April 2025) — numbers that reflect what happens when machine learning processes transaction signals at a scale and speed no rule set can match. Sardine's behavioral biometrics layer delivered 34.8% reduction in account takeover while simultaneously reducing false positives (Sardine, 2025).
This article goes deep on the fraud layer specifically — model architectures, feature engineering, regulatory constraints, and build-vs-buy decisions. For the broader view of AI across the full payments stack (routing, treasury, agentic flows), that overview covers all layers at breadth. For the specific question of rule engines vs ML hybrid design, that companion piece covers fraud system architecture in detail.
The fraud model landscape is not monolithic. There are distinct layers — transaction-level fraud scoring, account takeover prevention, behavioral biometrics, and compliance-adjacent AML detection — that require different model architectures, different feature sets, and in the EU, different regulatory treatment under the EU AI Act's risk classification — which determines which fraud-detection models face documentation and governance obligations from August 2026 onward. Operators building or buying fraud detection need to understand where they are in this stack and what the production reality looks like, not the vendor marketing version. Operators evaluating the buying decision specifically — whether to use a guarantee/liability-shift model, managed decisioning, or risk scoring — should start with the fraud prevention platform comparison.
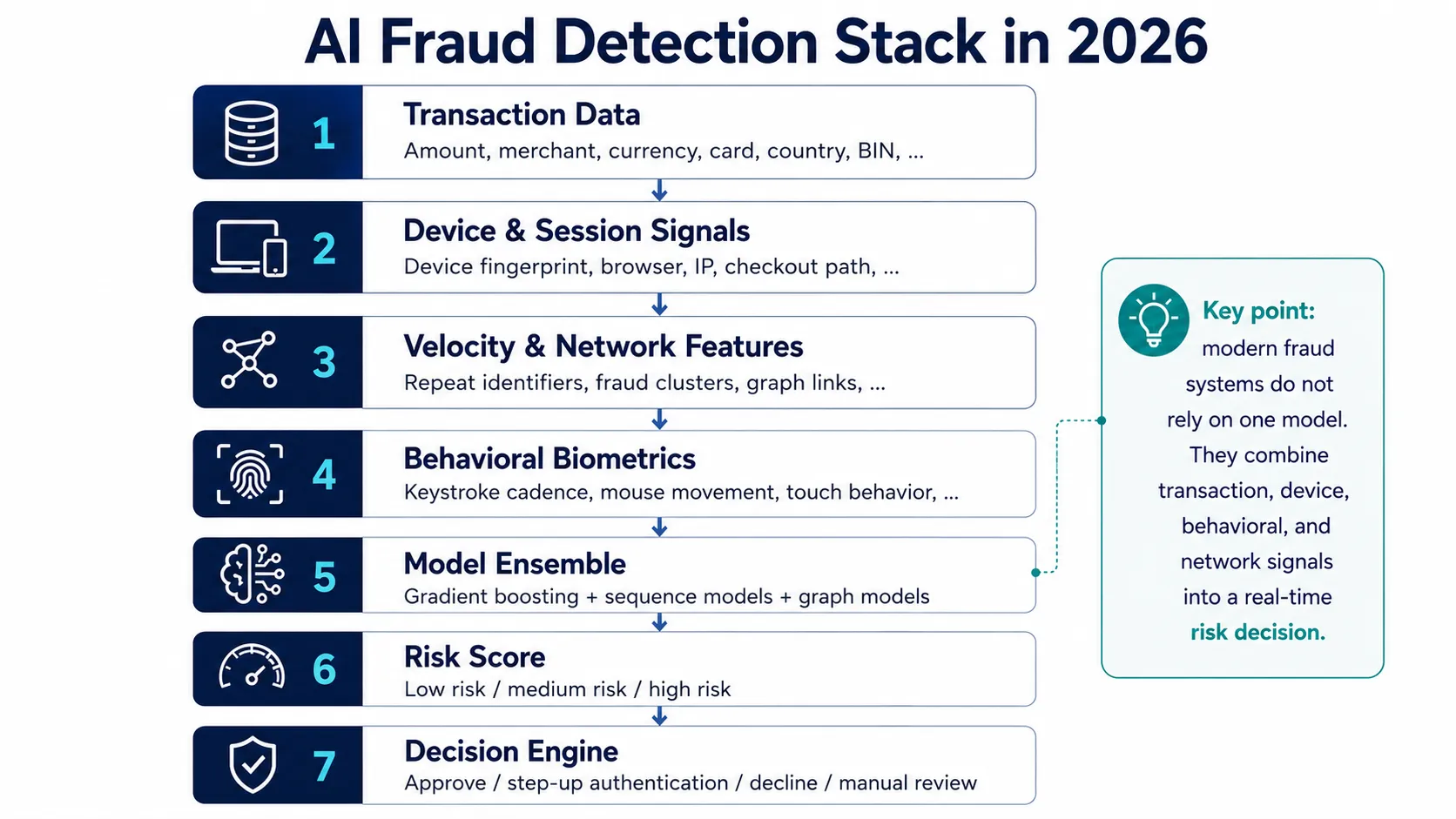
Production fraud detection is a 7-layer ensemble — not a single model. Each layer feeds the next, from raw transaction signals to a final approve/decline decision.
The Feature Engineering Layer: What Models Actually See
The quality of a fraud model is a function of its features as much as its architecture. Most transaction-level fraud models in production process three categories of signals:
Velocity and Network Features
Velocity check features track how frequently an identifier — IP address, device fingerprint, card BIN, email address, shipping address — appears in the transaction stream relative to historical patterns. High velocity on a new device fingerprint with a fresh shipping address is a strong fraud signal; high velocity on a known device fingerprint with an established shipping address is likely a legitimate high-value customer.
Network features extend velocity beyond single identifiers to entity relationships. A graph model might detect that a new IP address shares infrastructure characteristics with a known fraud IP cluster, or that a device fingerprint has been associated with cards that triggered chargebacks at other merchants in the network. Stripe's cross-network advantage — seeing fraud patterns across millions of merchants — is what makes its network graph features particularly strong. A fraudster who has never touched Stripe gets a clean signal; a fraudster who burned a card at one Stripe merchant gets flagged across the network.
Device and Session Features
Device fingerprinting captures browser characteristics, operating system, screen resolution, font rendering, and a variety of other signals that together create a near-unique identifier for a device. The signal degrades when browsers implement fingerprinting protections (Firefox, Brave, Safari all do this to varying degrees), but for most transactions the device signal remains strong.
Session behavioral features go beyond the device: how long did the user spend on the page before submitting? Did they copy-paste the card number or type it? What was the navigation path through the checkout? Fraudsters working at scale use automation scripts — they don't spend three minutes browsing before submitting 50 stolen card numbers. The temporal patterns of human checkout behavior are different from automated submission patterns in ways that are difficult to fake at scale.
Behavioral Biometrics
Behavioral biometrics is the most granular signal layer, capturing patterns in how users physically interact with devices: keystroke cadence (timing between keystrokes, not the keys themselves), mouse trajectory and acceleration, touch pressure and motion sensor data on mobile. BioCatch, Sardine, and NeuroID all operate at this layer.
In production, behavioral biometrics excel at detecting account takeover scenarios where an attacker has obtained valid credentials. The account owner's behavioral profile — their unique pattern of interaction built over hundreds of sessions — doesn't transfer to the attacker. A login with correct credentials but anomalous behavioral patterns triggers elevated risk scoring without requiring additional verification until a threshold is crossed.
Sardine collects over 3,000 distinct behavioral signals and builds per-user profiles that flag deviations. The 34.8% ATO reduction it reported is achieved not by blocking logins but by inserting friction — step-up authentication — precisely when behavioral deviation exceeds the model's risk threshold.
Model Architectures in Production
Transaction-level fraud scoring at major PSPs (Stripe, Adyen, Checkout.com) uses ensemble models: gradient boosting (XGBoost, LightGBM) for tabular feature scoring, combined with deep learning models for sequence features (transaction history, session event sequences) and graph neural networks for network relationship features.
Stripe's May 2025 announcement of a foundation model for payments represents the most visible shift in this architecture (TechCrunch, May 2025). The foundation model approach — training a large transformer-based model on tens of billions of Stripe transactions to capture general payment patterns, then applying it across fraud, authorization, and disputes — mirrors how large language models are adapted for domain tasks. Stripe reported the model raised card-testing attack detection rates from 59% to 97% on large users (Stripe Sessions, May 2025). The tradeoff is model complexity, inference latency, and the explainability problem (relevant for EU AI Act compliance).
Sift and Sardine operate primarily with gradient boosting ensembles for their core transaction scores, with behavioral biometrics as a separate scoring layer that feeds into the overall risk decision. Featurespace uses adaptive behavioral analytics — models that update per-customer in near-real-time as new transactions arrive, rather than periodic batch retraining.
The False Positive Economics
A critical metric that vendors understate: false positive rate. A fraud model that declines 10% of legitimate transactions is not a good fraud model, even if it catches 95% of fraud. For most e-commerce merchants, the revenue impact of false positives exceeds the revenue impact of actual fraud losses.
The standard benchmark: the industry average CNP false positive rate is approximately 15–30 false declines per one true fraud prevented. The best-in-class models — Stripe Radar, Adyen's fraud module, and specialized vendors like Kount/Equifax — operate at 5–10 false declines per prevented fraud event. The difference in conversion rate terms is typically 0.3–1.5% of total transaction volume — meaningful for any merchant processing significant volume.
The EU AI Act: What High-Risk Classification Means
The EU AI Act classifies certain AI systems as "high-risk" under Annex III. Importantly, pure fraud detection AI is explicitly excluded from the high-risk category (EU AI Act Annex III, Point 5(b) exception) — the exemption applies to AI systems used specifically to detect financial fraud (European Commission, 2025). However, if a fraud detection system also makes access decisions (blocking accounts, restricting services) or profiles users beyond fraud signals, it may fall into the high-risk category under the broader financial services provisions. Mandatory compliance requirements for high-risk systems take effect August 2, 2026 (EU AI Act).
What the Act Requires for In-Scope Systems
Operators deploying AI fraud detection that falls within the high-risk category (e.g., systems making access decisions) for EU transactions must implement:
Technical documentation: A complete description of the model's purpose, training data, validation methodology, and performance metrics. This is not a one-time disclosure — it must be updated when the model changes materially.
Continuous risk management system: A formal process for identifying, assessing, and mitigating risks from the AI system's decisions, including monitoring for performance degradation and demographic bias.
Automatic logging: Transaction-level logs that can be used to reconstruct the model's decision for any specific transaction, with retention requirements adequate for post-hoc audit. For fraud systems, this typically means storing the feature vector and model score for declined or flagged transactions.
Conformity assessment and EU database registration: Before deploying a high-risk AI system commercially in the EU, providers must complete a conformity assessment (self-assessment for most fraud systems under current guidance) and register the system in the EU's AI database.
Explainability for automated decisions: When AI-driven decisions affect individuals (a declined card transaction, a frozen account), EU individuals have rights analogous to GDPR Article 22 — the right to understand the logic of automated decisions. This creates a direct tension with black-box model approaches.
The Vendor Compliance Picture
Most major fraud detection vendors have begun publishing AI Act compliance roadmaps. Stripe's Radar documentation includes feature importance outputs that can partially satisfy explainability requirements. Sardine publishes model cards. But the August 2026 deadline is creating a compliance sprint — operators using custom-built models or white-labeled vendor solutions need to verify that their vendor's compliance posture covers their specific deployment.
The fines for non-compliance are material: up to €35 million or 7% of global annual turnover for prohibited AI practices, and up to €15 million or 3% of turnover for other violations (EU AI Act, 2024). For operators whose fraud systems cross into the high-risk category, the AI Act is an unavoidable constraint. For operators running pure fraud detection (no access decisions), the practical path remains using compliant PSP-level fraud tooling (Stripe Radar, Adyen's built-in fraud) and monitoring whether the fraud detection exemption holds under evolving regulatory guidance.
Building vs Buying
The buy-vs-build decision in fraud detection has moved significantly toward "buy" over the past three years, even for large merchants. The reasons are structural: the network effect of cross-merchant fraud signal sharing (which only PSPs and specialized vendors have), the ongoing cost of model retraining as fraud patterns evolve, and now the EU AI Act compliance overhead.
The operators who should build are those with:
- Highly specific business models where general fraud models perform poorly (certain digital goods categories, regulated gambling, crypto)
- Transaction volumes above $5 billion per year where marginal improvement in false positive rate generates meaningful revenue
- In-house ML engineering capacity already deployed on related problems
For everyone else, the math favors using Stripe Radar, Adyen's risk module, or a specialized overlay like Sift or Sardine for account-level risk, and investing internal engineering resources in model calibration (tuning the vendor's thresholds for your specific transaction profile) rather than model construction.
The frontier in 2026 is not better transaction-level fraud models — those are largely solved for sophisticated operators. It's real-time adaptive models that respond to fraud pattern shifts in hours rather than days, and multimodal models that combine transaction, behavioral, and device signals in a single inference pass rather than a decision tree of sequential checks. One fraud type that remains structurally difficult for transaction models is synthetic identity fraud, where fictitious identities pass verification and build legitimate-looking histories before exploiting them.