Fraud Prevention Platforms Compared: Guarantee, Managed Decisioning, and Risk Scoring Models
Sift, Forter, Riskified, Signifyd, and Kount compared by operating model: guarantee, managed decisioning, and risk scoring — which fits your fraud operation.
Fraud-platform selection is a model decision, not a vendor decision: guarantee/liability-shift, managed decisioning, or risk scoring. Each transfers different liability and control. Match to your fraud maturity and chargeback exposure — not vendor marketing.
Fraud prevention platform selection is routinely framed as a vendor question. It is not. The decision that matters is which operating model fits your fraud maturity, team structure, margin tolerance, and chargeback exposure — and vendor selection follows from that. Getting the model wrong is more expensive than getting the vendor wrong.
Three models account for the dominant platforms in the market. Guarantee/liability-shift vendors approve or decline orders and assume chargeback liability on approved transactions for a fee. Managed-decisioning vendors automate the approve/decline call and offer contractual commitments on approval and chargeback outcomes, without purely insuring the outcome. Risk-scoring/decisioning vendors return a score or recommendation that the merchant's team acts on, keeping the decision and the chargeback liability in-house.
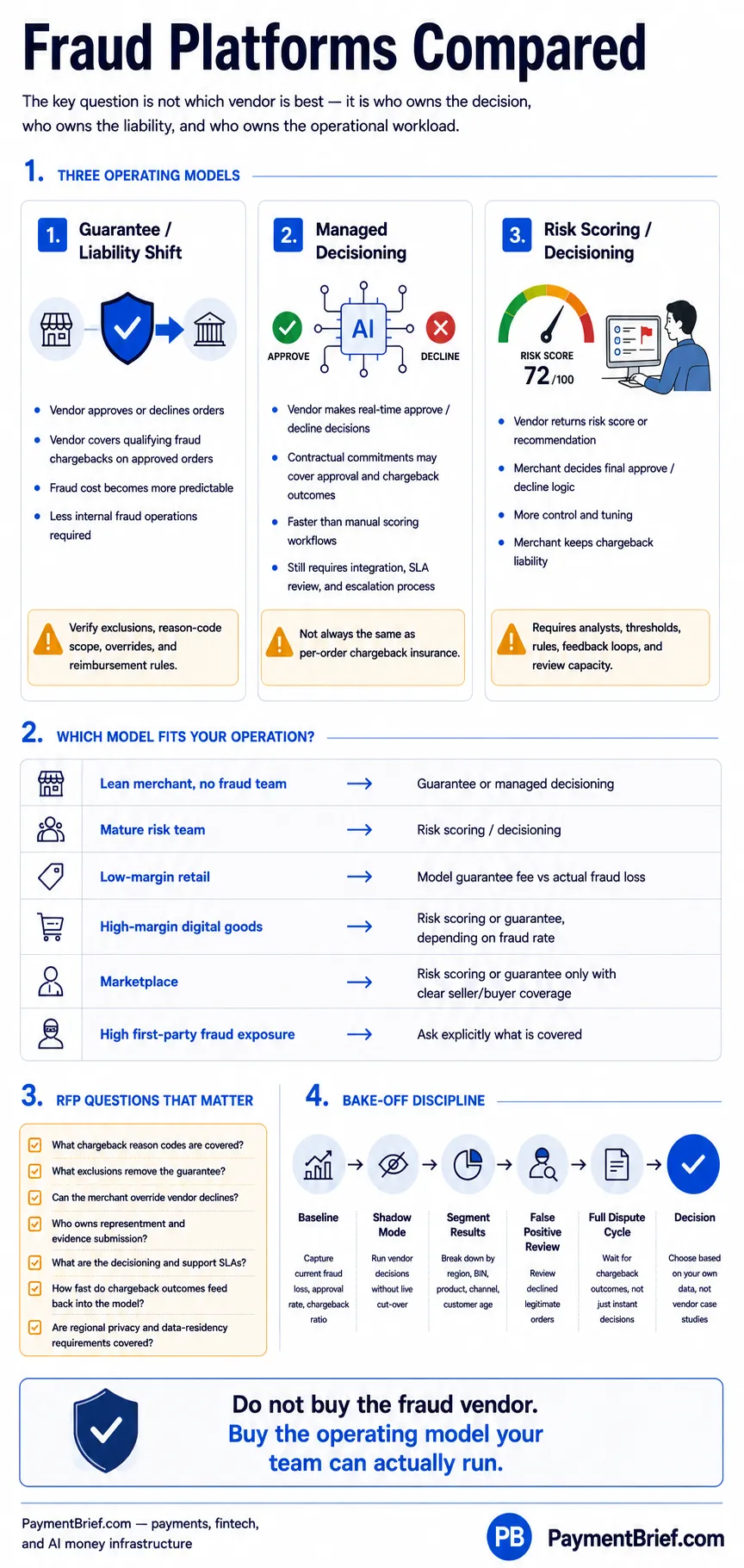
The three fraud prevention platform operating models — guarantee/liability-shift, managed decisioning, and risk scoring — mapped to how decision-making and liability are split between vendor and merchant.
Fraud tools vs chargeback tools
Fraud prevention platforms and chargeback management platforms get evaluated as if they compete for the same budget line. They don't. They sit at different points in the same dispute lifecycle, and a mature fraud operation typically runs one of each rather than picking a single winner across categories.
Pre-auth fraud scoring is what this article compares: Signifyd, Riskified, Forter, Kount, and Sift all operate before authorization, either deciding to approve or decline the transaction directly or returning a score your team acts on — depending on the operating model above. This layer determines how much fraud reaches your books in the first place.
Pre-dispute deflection sits one stage later — after a transaction is authorized but before a chargeback files. Verifi (Visa) and Ethoca Alerts (Mastercard) are network-side programs, not merchant SaaS: they let an issuer's dispute inquiry get resolved — a refund, a credit, a data exchange — before it converts into a formal chargeback.
Post-chargeback representment is the final stage. Chargeflow and Justt (merchant-configured automation) and Chargebacks911 (managed service) contest chargebacks that have already been filed.
Comparing a fraud-scoring vendor against a representment vendor is a category error — they solve different problems on opposite sides of the authorization line. For the deflection and representment layers in depth, see how to compare chargeback management platforms.
The short answer
If your fraud team is lean or non-existent, and predictable fraud cost matters more than optimising to the lowest possible fraud rate, a guarantee or managed-decisioning model reduces operational lift and makes fraud cost a line item rather than a variable. If you have a mature risk function with analysts, rules infrastructure, and the appetite to own decisions, a risk-scoring model gives you control and customisation at lower total cost — assuming your fraud rates support it.
The comparison below covers five vendors that publicly position across these models. All claims are sourced from vendor product pages accessed on 2026-05-30. Verify each vendor's current positioning, coverage scope, pricing structure, and exclusions directly — these change, and published marketing metrics are vendor-reported, not independent benchmarks.
The three models explained
Guarantee / liability-shift
The vendor approves or declines each transaction. On orders the vendor approves, it assumes financial liability for fraud chargebacks. The merchant pays a fee on approved orders and receives reimbursement when an approved order generates a qualifying chargeback.
What this changes operationally: fraud cost becomes a predictable fee rather than a variable loss rate. The vendor is incentivised to approve legitimate orders accurately — they bear the loss if they approve fraud. Dispute operations (representment, evidence collection) may be handled by the vendor, reducing in-house chargeback team requirements.
What this does not change: non-fraud losses (operational errors, policy abuse, refund abuse, first-party fraud) are not automatically covered — coverage scope and exclusions are commercial terms, not published on product pages. Verify these directly.
Vendors publicly positioning in this model (as of 2026-05-30): Riskified, Signifyd.
Managed decisioning
The vendor automates the approve/decline decision using AI, machine learning, and identity-graph data. Rather than pure liability insurance, vendor materials describe contractual commitments covering approval rates, chargeback rates, and response time SLAs — a performance-based model rather than a per-order guarantee.
What this changes operationally: the vendor makes real-time decisions without requiring the merchant to act on a score. The contractual commitment is on outcomes (approval and chargeback rates), not on per-order reimbursement in the same structure as a guarantee model. Dispute management may be available as a separate product.
What this does not change: the merchant still needs to configure the integration, handle edge cases, and maintain a working relationship with the vendor's dispute/chargeback team. Liability mechanics differ from a pure guarantee — verify the exact contractual structure.
Vendors publicly positioning in this model (as of 2026-05-30): Forter.
Risk scoring / decisioning
The vendor returns a fraud score, risk indicators, and/or a recommendation. The merchant's own team — or the merchant's internal rules engine — makes the final approve/decline decision and retains chargeback liability. The vendor provides the intelligence layer; the merchant owns the decision and its consequences.
What this changes operationally: control and tuning sit with the operator. A risk team can override scores, segment decisioning by product or channel, and build custom rules on top of the vendor score. Case management tooling helps analysts review flagged transactions.
What this does not change: the merchant requires internal capacity to act on signals, set thresholds, investigate false positives, and tune decisioning logic. There is no liability transfer; fraud losses remain the merchant's responsibility.
Vendors publicly positioning in this model (as of 2026-05-30): Sift, Kount (Equifax).
Vendor comparison
Important sourcing note. Claims in this table are drawn from vendor product pages accessed 2026-05-30. Vendor positioning, products, and commercial terms change. Re-verify at evaluation time. Marketing performance metrics (detection rates, chargeback-reduction percentages, approval-uplift figures) are excluded — these are vendor-reported, vary by customer base, and are not independent benchmarks.
| Dimension | Sift | Forter | Riskified | Signifyd | Kount (Equifax) |
|---|---|---|---|---|---|
| Model (publicly stated) | Risk scoring / decisioning | Managed decisioning | Guarantee / liability-shift | Guarantee / liability-shift | Risk scoring / identity trust |
| Chargeback liability assumption | No — merchant retains liability | Contractual commitments on approval + chargeback rates; not a per-order insurance model (verify terms) | Yes — on individually approved orders (verify exact scope, exclusions) | Yes — fraud + non-fraud incl. INR/SNAD on approved orders (verify exact scope) | No — merchant retains liability |
| Who makes the approve/decline call | Merchant team acts on score | Vendor (automated, real-time) | Vendor (approve/decline per order) | Vendor (approve/decline per order) | Merchant team acts on score / identity-trust output |
| Data network (vendor-stated) | Consortium network (1T+ signals, 34k+ sites — vendor-stated) | Cross-merchant identity graph (1.2B+ identities — vendor-stated) | Not stated on product pages reviewed | Signifyd Commerce Network (vendor-stated) | Equifax Digital Identity Global Network; Kount 360 platform |
| Case management / review tooling | Case management and reporting tools (publicly stated) | Dispute Management product (separate); verify scope | Dispute Resolve (representment handled by Riskified); Policy Protect for abuse (separate product) | Verify — not detailed on reviewed pages | Verify — not detailed on reviewed pages |
| Pricing model | Not publicly disclosed | Not publicly disclosed | Fee on approved orders (model publicly stated; rate not disclosed) | Not publicly disclosed | Not publicly disclosed |
| Vertical positioning (general; verify directly) | Broad e-commerce, fintech, marketplaces, digital goods | E-commerce, retail, digital; enterprise focus | E-commerce focus; Shopify and enterprise integrations stated | E-commerce, including Shopify; broader commerce | Broad; payments, identity, account protection; Equifax integrations |
| Parent / ownership | Independent | Independent | Independent | Independent | Equifax (acquired) |
Evaluating vendors head-to-head
The query that brings most readers to this page is a "vendor A vs vendor B" search — Forter vs Riskified, Signifyd vs Riskified, Sift vs Riskified, Kount vs Signifyd, and the same pairs in reverse order. None of these pairs has a publicly correct answer, because none of the underlying performance numbers are public. What follows is what to evaluate, not who wins.
Dimensions that matter for any pair:
- Decision latency and where the decision sits. Some vendors decide inline at checkout; others return a score your team acts on afterward. This is the operating-model axis covered above, and for a head-to-head it is the first question — it determines whether you are comparing two decision engines or a decision engine against a scoring tool.
- Guarantee vs decisioning-only posture. Does the vendor assume chargeback liability on approved orders, commit contractually to approval/chargeback outcomes, or return a score and leave liability with you? Similar guarantee language can still hide different exclusions and reason-code scope — ask for the full exclusion schedule, not the marketing page.
- Pricing model shape. Fee on approved GMV, per-transaction scoring fee, or a guarantee premium — the shape matters more than any published rate, since none of the five vendors here disclose rates. Evaluate fit against your margin structure, not a number you cannot get anyway.
- Integration surface. Platform/PSP plugin depth versus API-first integration changes time-to-live and maintenance burden. Ask each vendor for their current integration list against your stack — public pages understate this.
- False-positive handling and appeal loops. Ties to the RFP checklist below — a vendor that wins on headline catch rate but has a slow, opaque override process can cost more in blocked good customers than it saves in fraud.
- Data-network scale. Vendors publish network size (identities, sites, signals) as a quality proxy. Treat it as a question to verify at evaluation time, not a comparable metric — vendors define "identity" and "signal" differently, and the figures are vendor-reported.
On the specific pairs: Forter vs Riskified is a managed-decisioning-vs-guarantee comparison, not two versions of the same product — evaluate posture fit, not which vendor "performs better" in the abstract. Signifyd vs Riskified are both guarantee-model vendors; the real evaluation is coverage scope and reason-code exclusions, which sit in the RFP rather than the public page. Sift vs Riskified and Kount vs Signifyd are both risk-scoring-vs-guarantee comparisons — the "vs" query itself usually reflects a model question (own the decision, or transfer it) rather than a feature comparison between comparable products. Riskified vs Forter and Riskified vs Signifyd are the same comparisons in reverse order; query direction doesn't change the evaluation.
None of these pairs should resolve to a declared winner. The honest method is a parallel bake-off on your own traffic, per the methodology below, run against two or more vendors in shadow mode at once — vendor-published performance claims aren't comparable to each other because they're measured against different traffic bases and different definitions of a "catch." Your own numbers, on your own traffic, are the only numbers that resolve a head-to-head.
What public pages do not tell you — and what to ask in the RFP
The comparison table captures publicly verifiable positioning. The following dimensions determine day-to-day operational reality and financial exposure — and none are available from product pages. Take these as your RFP checklist.
Liability scope and exclusions What categories of chargeback are excluded from the guarantee or contractual commitment? Common exclusion areas: orders the vendor declined but the merchant approved via override; orders placed using the merchant's own gift cards or credits; transactions in specific geographies; orders that failed to meet data submission requirements. Ask for the full exclusion schedule in writing.
Covered vs non-covered chargeback reason codes Signifyd's public pages explicitly mention INR and SNAD coverage. Riskified's pages reference "any chargebacks" with specific exclusions in their support documentation. Neither publishes a full reason-code coverage matrix. For risk-scoring models (Sift, Kount), the merchant bears all liability regardless of reason code — the question shifts to how the score integrates with your dispute operations. Ask each guarantee/decisioning vendor for a complete list of covered Visa and Mastercard reason codes.
First-party fraud and friendly fraud First-party fraud — a customer making a legitimate purchase and then disputing it — is typically the hardest category to cover under a standard fraud guarantee, because it generates a chargeback with a dispute reason code that looks like the customer never authorised the transaction. Riskified's Policy Protect is a separate product for this category. Ask vendors explicitly whether first-party fraud chargebacks are covered, and under what evidentiary standard they will contest a dispute filed by a returning customer.
INR, service disputes, refund abuse, and policy abuse Item Not Received (INR) and Significantly Not As Described (SNAD) generate chargebacks under non-fraud reason codes and require different evidence to contest. Refund abuse (requesting a refund after consuming goods or services) and policy abuse (exploiting return/cancellation policies) may not generate chargebacks at all — they affect refund rates and margin, not chargeback ratios. Verify which products within each vendor's portfolio cover which abuse type, and what the operational handoff looks like.
Merchant override rights Can you approve a transaction the vendor has declined? For guarantee models, overriding a vendor decline typically removes the guarantee on that order — the liability remains with the merchant. The commercial terms around overrides (how many, which categories, what documentation) are not on product pages. For managed-decisioning models, the override architecture is similarly RFP-level.
Who owns representment and evidence submission Riskified's Dispute Resolve explicitly positions as handling representment on the merchant's behalf. Forter has a Dispute Management product. For risk-scoring models, representment remains the merchant's responsibility — assess your internal chargeback team capacity against the expected dispute volume your platform choice creates. Ask each vendor what their representment win rate is for their managed service, and how they handle disputes in markets where you do not have a local entity.
SLA and support model Response time SLAs for transaction decisions are listed by some vendors; support SLAs for operational issues, escalations, and dispute handling are not. Implementation support depth (dedicated CSM, self-serve documentation, managed onboarding) varies and directly affects time-to-live and post-launch fraud coverage.
Regional and data privacy considerations GDPR, CCPA, and local data residency requirements affect what data can be shared with a US-headquartered vendor, how model training data is used, and whether EU-specific product versions are available. Kount's Equifax lineage adds credit-bureau data questions in some jurisdictions. Verify the vendor's data processing agreements, sub-processor lists, and regional product coverage before finalising contracts for non-US markets.
Feedback loop from chargebacks, refunds, and disputes How quickly does chargeback and dispute outcome data flow back into the vendor's model to improve future decisions? For guarantee models, the vendor absorbs the loss and is self-incentivised to close the loop. For risk-scoring models, closing the feedback loop requires the merchant to push dispute outcome data back to the vendor — verify the data ingestion mechanism and the lag between dispute resolution and model update. A slow feedback loop on a high-velocity fraud pattern is a direct gap.
How to run a fraud platform bake-off
Vendor case studies are marketing artefacts. A bake-off gives you your own numbers against your traffic base.
Before you start: establish baselines. Run your current fraud stack for at least 30 days before the bake-off and capture: fraud loss rate (basis points of GMV), chargeback ratio by count and by value, approval rate on attempted transactions, manual review rate, false-positive rate (sample-reviewed legitimate orders incorrectly flagged), dispute win rate by reason code, and average order value by channel. These are your comparison denominator. Without them, you are comparing against vendor marketing materials — not against your own operation.
Shadow-mode testing. Run the new platform in shadow mode: it receives your transaction data and makes decisions, but your existing system retains the live decision. Capture the shadow platform's approve/decline recommendations alongside your live decisions. Compare outcomes over a full dispute cycle (typically 90–120 days for chargebacks to resolve) before cutting over any live traffic.
Segment everything. Do not evaluate on blended metrics. Segment by: geographic region (fraud patterns differ materially by market); BIN range (issuer region affects false-positive rates); product type (digital goods vs physical goods have different fraud profiles); traffic source (direct vs affiliate vs marketplace); customer age (new vs returning — new account fraud and first-party fraud cluster differently); and transaction size band. A platform that outperforms on blended approval rate but underperforms on new-customer conversion in your highest-growth market has a negative net impact on the business you care about.
False-positive review. Assign an analyst to manually review a sample of orders the shadow platform declines — especially orders your current system approves. This is the only way to get a false-positive rate estimate that is not vendor-reported. Expect this to be the most resource-intensive part of the bake-off, and the most important for understanding the actual customer experience impact.
Manual-review workload. For risk-scoring platforms, measure the volume of transactions that land in the manual review queue (below the auto-approve threshold, above the auto-decline threshold). If the bake-off platform generates significantly more manual-review volume than your current setup, account for the analyst time this creates before calculating net benefit.
Chargeback feedback loop. Do not cut the bake-off at 30 days. Fraud detection accuracy only becomes visible when the dispute cycle closes — Visa's chargeback window is typically 120 days from the transaction date, and SEPA dispute windows differ further. Run the shadow phase long enough to see outcome data on transactions, not just decision data.
Do not rely only on vendor case studies. Vendor case studies select for successful deployments in comparable verticals. They represent the vendor's best results, not your likely results. Use them to understand the ceiling; use your own bake-off data to understand the floor.
Selection matrix by merchant archetype
| Archetype | Operating model fit | Rationale |
|---|---|---|
| Lean merchant, no in-house fraud team | Guarantee or managed decisioning | No internal capacity to act on scores; outsourced decision reduces operational risk. Guarantee model makes fraud cost predictable. |
| Mature risk team with analyst capacity | Risk scoring / decisioning | Team can act on scores, tune rules, and investigate false positives. Control and customisation are worth more than the predictability premium. |
| High-margin digital goods | Risk scoring or guarantee — depends on fraud rate | High margins can absorb guarantee fees if fraud is hard to detect. If fraud rate is already low, risk-scoring may be more economical. Digital goods have higher first-party fraud and policy-abuse exposure — confirm how the model handles these. |
| Low-margin retail | Careful evaluation of guarantee fee economics | Guarantee fee as a percentage of approved GMV may compress margin more than the fraud loss it replaces. Model the break-even explicitly: if your fraud loss rate is X basis points and the guarantee fee is Y, the guarantee only makes economic sense when Y < X + operational cost of running your own fraud operations. |
| Marketplace | Risk scoring — or guarantee with clear seller-vs-buyer coverage scope | Marketplace fraud patterns (seller-initiated fraud, buyer collusion, refund abuse) may not fit standard guarantee models. Verify whether the vendor's model covers transactions where the merchant is not the seller of goods. |
| High first-party fraud exposure | Ask about first-party fraud handling explicitly before choosing any model | First-party fraud generates chargebacks that look like unauthorised transactions. Standard fraud guarantees may not cover these. Vendors with dedicated policy-abuse or friendly-fraud products (such as Riskified's Policy Protect) address this separately. Do not assume first-party fraud is covered under a standard guarantee. |
What this article does not cover
Performance numbers — detection rates, approval-uplift percentages, chargeback-reduction statistics — are absent by design. All published figures in this space are vendor-reported, vary by customer base and traffic mix, and are not independently audited. Using them to compare vendors would give false precision. Your bake-off methodology produces the only numbers that are valid for your business.
Pricing is not covered because no vendor publicly discloses pricing in sufficient detail to compare. Guarantee fees as a percentage of approved GMV, scoring fees per transaction, and enterprise contract structures require direct vendor engagement.
For the mechanics of how fraud detection models work under any of these platforms, see real-time fraud decisioning, rule engines vs ML hybrid architecture, and AI fraud detection in 2026.
For how to measure your fraud operations once a platform is in place, see the fraud operations KPI scorecard.
For understanding the chargeback exposure that platform selection affects, see chargeback operations KPIs and the true cost of a chargeback.
For the dispute-side counterpart to this guide — alert networks, representment automation, and managed recovery compared by operating model — see how to compare chargeback management platforms.
Sources & methodology (16)
Sift publicly positions as a risk-scoring/decisioning platform; merchants act on Sift's real-time risk scores rather than Sift assuming chargeback liability
Checked:
Sift references a global network of over 1 trillion data signals across 34k+ sites and apps as the basis for its risk scores
Vendor-stated figure; not independently verified
Checked:
Forter publicly positions as automated/managed real-time decisioning; vendor materials state it offers guaranteed results on fraud chargebacks, approval rates, and response time SLAs
Checked:
Forter's public materials explicitly contrast its model with fraud insurance, framing its guarantee as covering both approval rates and chargeback rates rather than reimbursing after the fact
Checked:
Forter references 1.2B+ identities in a cross-merchant dataset as the basis for its decision engine
Vendor-stated figure; not independently verified
Checked:
Riskified publicly positions its chargeback guarantee as: 'Pay only for approved orders that generate revenue. We guarantee approval rates and cover any chargebacks.' Only individually approved orders are guaranteed.
Checked:
Riskified Dispute Resolve publicly positions as handling representment — automatically collecting compelling evidence and managing chargeback disputes on behalf of merchants
Checked:
Riskified Policy Protect is a separate product for policy abuse and friendly fraud; it is not part of the core chargeback guarantee
Checked:
Signifyd publicly positions its Complete Chargeback Protection as providing a financial guarantee against fraud and non-fraud chargebacks including INR and SNAD on all approved orders
Checked:
Signifyd references the Signifyd Commerce Network as a data foundation for its guarantee model
Checked:
Kount operates as part of Equifax following acquisition; the Kount 360 platform positions as AI-driven identity trust and fraud scoring; no chargeback guarantee is publicly stated
Checked:
Verifi's pre-dispute products (Order Insight and related tools) operate before a chargeback is filed, sharing order data with issuers to resolve a dispute inquiry at the point of customer contact; positioned as a Visa network program accessed via the merchant or acquirer, not standalone merchant SaaS
Checked:
Ethoca Alerts is a Mastercard network program connecting merchants, acquirers, and issuers to share fraud and dispute data before a chargeback is filed, enabling the merchant to resolve the case pre-chargeback (e.g., via refund)
Checked:
Chargeflow publicly positions as merchant-configured, automated software that contests chargebacks after they have already been filed (representment), on contingency-only pricing
Checked:
Justt publicly positions as AI-powered representment automation operating after a chargeback has been filed, with contingency-only pricing (fee charged only on successful recovery)
Checked:
Chargebacks911 publicly positions as a team-led, full-service managed chargeback/representment operation rather than self-serve software, operating on chargebacks that have already been filed
Reused from the sister article's sourcing pass (original access 2026-05-30); a fresh fetch attempted 2026-07-07 for this upgrade returned no usable body content (template/placeholder response, likely bot-protection), so the earlier confirmed access date is retained rather than fabricating a new one for the same fact
Checked:
Source types explained in our Methodology.